Knowledge Distillation at a Low LevelWe’ve all heard about knowledge distillation and how it helps in making models smaller by sacrificing a bit of performance. Essentially, it…Jan 241Jan 241
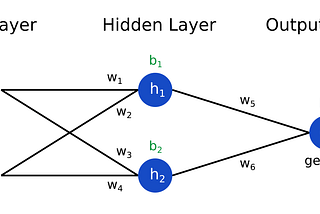
ML4LM — Fine-Tune Smarter, Not Harder: Discover LoRA for LLMsWhen fine-tuning a Large Language Model (LLM), instead of adjusting all the original weights, we can train a smaller set of new weights…Nov 15, 2024Nov 15, 2024
ML4LM — Mastering Anomaly Detection in Production: When to use and when not to useProblem: Detecting Anomalies in DataNov 7, 2024Nov 7, 2024
ML4LM-Content Based Recommendation SystemsUnderstanding Content-Based Recommendation SystemsSep 16, 2024Sep 16, 2024
ML4LM — MLE vs Bayesian intuitive Insights, No Math!Maximum Likelihood Estimation (MLE): Relying on Observed DataMar 5, 2024Mar 5, 2024
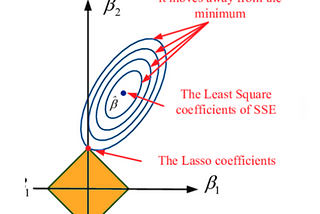
ML4LM- How does Lasso bring sparsity?Many of us have heard about Lasso and its ability to bring sparsity to models, but not everyone understands the nitty-gritty of how it…Dec 25, 2023Dec 25, 2023
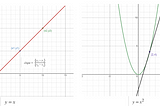
ML4LM — What are Derivatives?“Back in my school days up to the 10th grade, I had a genuine love for math. Whether it was tackling geometry, diving into trigonometry…Dec 22, 20231Dec 22, 20231
ML4LM-Feature Scaling- NormalizationEver wondered how data gets its makeover before revealing its insights? Enter the battleground of data refinement, where normalization and…Nov 28, 2023Nov 28, 2023